智谱发布新一代基座模型GLM-4.5: 开源、高效、低价, 专为智能体而生
与早期追求参数规模的竞赛不同,GLM-4.5的发布重点突出地体现在三个方面:明确面向智能体(Agent)应用的设计、通过技术优化实现的高性价比,以及全面拥抱开源和开发者生态的战略布局。
之前在今年4月,智谱就发布了「AutoGLM沉思」——一个能探究开放式问题,并根据结果执行操作的自主智能体。今天GLM-4.5的推出,不仅是智谱自身模型矩阵的一次升级,也从一个侧面反映出AI行业发展的趋势性变化:模型的价值正在进一步加速向解决实际问题、降低应用门槛的方向迁移。
为「智能体」而生的模型设计
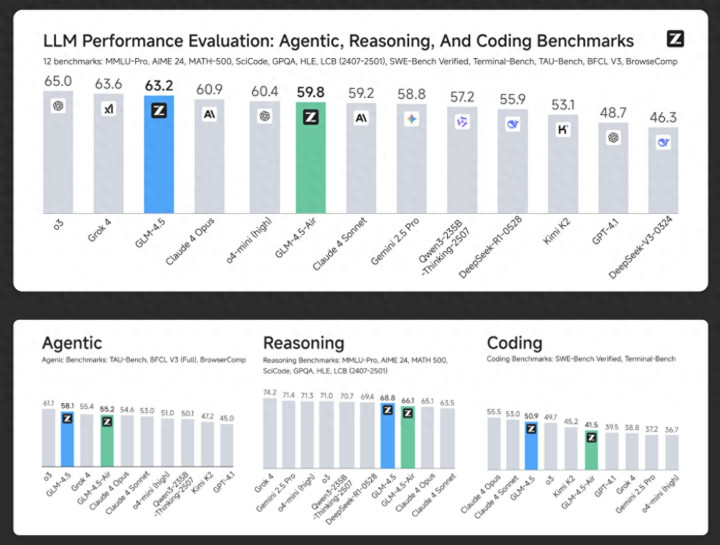
衡量一个大模型的优劣,综合能力基准评测是业内的通行做法。智谱此次公布了GLM-4.5在一系列评测集上的表现。这份评测涵盖了推理、代码、科学、智能体等12个不同维度的基准测试,旨在全面评估模型的综合素质。
根据智谱提供的数据,GLM-4.5在这些测试中的综合得分位列全球参评模型的第三位,在开源模型中排名第一。
优秀的评测成绩是模型能力的基础,但更值得关注的是其背后的设计理念。GLM-4.5从一开始就将目标锁定在「智能体应用」。智能体要求模型具备任务理解、规划分解、工具调用和执行反馈等一系列复杂能力,这超出了传统聊天机器人的范畴。
智谱将「在不损失原有能力的前提下融合更多通用智能能力」作为其对AGI的理解,而GLM-4.5正是这一理念的实践。
为了支撑智能体所需的强大而灵活的能力,GLM-4.5在技术架构上做出了针对性的选择:
混合专家(MoE)架构:GLM-4.5采用了MoE架构,总参数量达到3550亿,而单次推理中被激活的参数量为320亿。这种架构允许模型在保持巨大知识储备和能力上限的同时,能根据具体任务,只调用部分「专家」网络进行计算。其直接好处是在保证高质量输出的前提下,有效控制了推理成本和能耗,为大规模应用部署提供了可行性。 双模式运行:模型被设计为两种工作模式——「思考模式」和「非思考模式」。「思考模式」为复杂的推理和工具调用任务设计,允许模型投入更多计算资源进行深度规划;「非思考模式」则服务于需要快速响应的场景。这种设计兼顾了智能体在执行复杂任务时的「深度」与日常交互时的「速度」,是对实际应用场景需求的细致考量。 针对性数据训练:模型的训练过程也体现了其应用导向。在15万亿token的通用数据预训练之后,团队使用了8万亿token的高质量数据,在代码、推理、智能体等领域进行了针对性训练,并通过强化学习进行能力对齐。这种「通识教育+专业深造」的训练路径,旨在让模型不仅知识渊博,更在特定专业领域具备解决实际问题的能力。 综合来看,GLM-4.5并非一个泛泛的通用模型,其技术选型和训练策略都清晰地指向了构建高效、可靠的AI智能体这一具体目标,这也反映了智谱对大模型下一阶段应用形态的判断。 成本、效率与生态的商业逻辑 性能是技术层面的核心,而成本和生态则是决定一项技术能否被市场广泛接纳的关键。GLM-4.5在此次发布中,展现了清晰的商业逻辑。 首先是参数效率带来的成本优势。 「参数效率」是评估模型训练水平和架构设计的重要指标,即用相对更少的计算资源实现同等或更优的性能。智谱方面的数据显示,GLM-4.5的参数量显著低于部分业界同类模型,但在多项基准测试中表现更佳。在代码能力榜单SWE-bench Verified上,其性能与参数量的比值处于帕累托前沿,这证明了其较高的训练和推理效率。 更高的效率直接转化为更低的部署和使用成本。此次公布的API定价——输入0.8元/百万tokens,输出2元/百万tokens——显著低于当前市场主流闭源模型的定价水平。配合高速版可达100 tokens/秒的生成速度,GLM-4.5为开发者提供了一个兼具高性能和低成本的选择。