实锤!大模型不会真正的数学推理;微软开源实时交互式世界模型MineWorld|今日热门论文

速览热门论文
1. 实锤! 大模型不会真正的数学推理
2. 微软开源实时交互式世界模型 MineWorld
3. 字节:7B 高性能视频生成模型训练策略
4. CMU 团队提出「协作式 RAG」框架 CoRAG
5. 港大提出图像生成模型 PixelFlow:无需 VAE,可端到端训练
1. 实锤!大模型不会真正的数学推理
尽管 benchmark 分数很高,但大语言模型(LLM)经常在简单的问题上失败,这就提出了一个关键问题:LLM 是在学习数学原理,还是仅仅在记忆模式?
在这项工作中,来自浙江大学和西湖大学的研究团队没有设计更为复杂的 benchmark,而是使用基本的二进制加法(0 到 2^64)来研究这个问题,探究了两个核心特性:交换律(A B=B A)和组合泛化(通过同构符号映射,例如,7 映射为 y)。SOTA LLM 在数字加法上的准确率为 73.8�9.8%,而在符号映射下的准确率则下降到 7.5% 及以下,这表明所学规则的泛化失败。数字数量增加时的非单调性能变化,以及频繁的交换律违反(超过 1700 例“A B 不等于 B A”),进一步证明了这一点。明确提供加法规则会使性能平均下降 81.2%,而自我解释则能保持基线准确率,这表明 LLM 的算术处理与人类定义的原则不一致。

研究结果表明,当前的 LLM 依赖于记忆模式,而不是真正的规则学习,这凸显了架构上的局限性,以及需要新方法来实现真正的数学推理。
论文链接:https://arxiv.org/abs/2504.05262
2. 微软开源实时交互式世界模型 MineWorld
世界建模是智能 agent 与人类有效互动并在动态环境中运行的关键任务。
在这项工作中,微软研究院团队提出了一个基于 Minecraft 的实时交互式世界模型——MineWorld,其由视觉-动作自回归 Transformer 驱动,将配对的游戏场景和相应的动作作为输入,并根据动作生成相应的新场景。
具体来说,他们通过图像 tokenizer 和动作 tokenizer 将视觉游戏场景和动作转化为离散的 token ID,然后将这两种 ID 交错连接组成模型输入,再通过下一个 token 预测对模型进行训练,从而同时学习游戏状态的丰富表征以及状态和动作之间的条件。
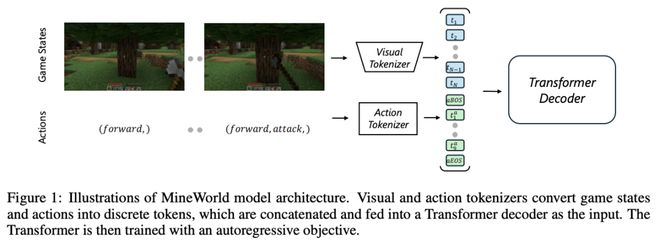
在推理方面,他们开发了一种新颖的并行解码算法,可同时预测每帧中的空间冗余 token,让不同规模的模型每秒生成 4 至 7 帧,实现与游戏玩家的实时互动。在评估中,他们提出了新的指标,不仅可以评估视觉质量,还可以评估生成新场景时的动作跟随能力,这对世界模型至关重要。
综合评估结果表明,MineWorld 的效果优于基于扩散的 SoTA 开源世界模型。
论文链接:https://arxiv.org/abs/2504.08388
3. 字节:7B 高性能视频生成模型训练策略
在这项工作中,字节跳动 Seed 团队介绍了一种具有成本效益的视频生成基础模型训练策略。他们介绍了一个拥有约 70 亿(7B)参数的中型研究模型,称为 Seaweed-7B,该模型使用 665000 H100 GPU 小时从头开始训练。尽管只使用了中等计算资源进行训练,但与规模更大的视频生成模型(如 Wan 2.1、HunyuanVideo)相比,Seaweed-7B 表现出了具有竞争力的性能。
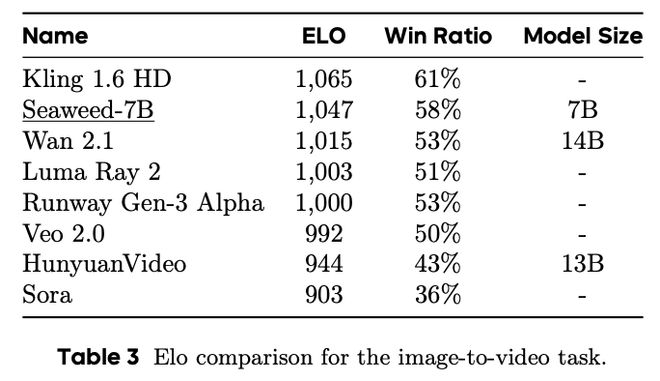
在资源有限的情况下,设计选择尤为重要。该技术报告重点介绍了提高中型扩散模型性能的关键设计决策。他们得出了两点结论:(1)Seaweed-7B 的性能可媲美甚至超越使用更多 GPU 资源训练的更大型模型;(2) Seaweed-7B 具有很强的泛化能力,可以通过轻量级微调或继续训练,有效适用于各种下游应用领域。
论文链接:https://arxiv.org/abs/2504.08685
4. CMU 团队提出「协作式 RAG」框架 CoRAG
检索增强生成(RAG)模型在知识密集型任务中表现出色,尤其是在少样本学习限制条件下。
在这项工作中,卡内基梅隆大学团队提出了一个将 RAG 扩展到协作环境的框架——CoRAG,其中多个 client 使用协作文本片段存储共同训练一个共享模型。

为了评估 CoRAG,他们还提出了一个用于协作同构开放域问答的基准——CRAB。实验证明,在资源匮乏的情况下,CoRAG 始终优于参数协作学习方法和本地训练的 RAG 模型。进一步的分析揭示了共享存储中相关文本片段的重要性、纳入无关文本片段的惊人优势以及硬否定对性能产生负面影响的可能性。这就为协作式 RAG 引入了一个新的考虑因素:利用集体丰富的知识库与纳入其他 client 的有害文本片段的潜在风险之间的权衡。研究结果强调了 CoRAG 的可行性,同时也突出了关键的设计挑战和未来研究的前景。
论文链接:https://arxiv.org/abs/2504.01883
5. 港大提出图像生成模型 PixelFlow:无需 VAE,可端到端训练
在这项工作中,香港大学团队提出了一系列直接在原始像素空间运行的图像生成模型 PixelFlow,其与主流的潜空间模型截然不同。
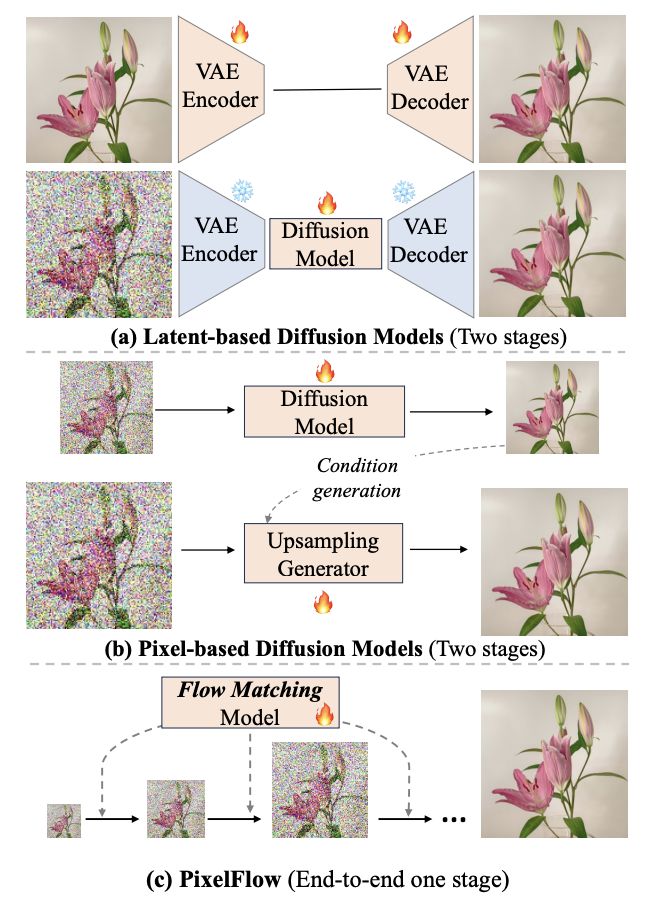
这种方法无需预训练变分自编码器(VAE),简化了图像生成过程,并使整个模型可以端到端训练。通过高效的级联流建模,PixelFlow 在像素空间内实现了可负担的计算成本。它在 256*256 ImageNet 类别条件图像生成基准上的 FID 达到了 1.98。文本到图像的定性结果表明,PixelFlow 在图像质量、艺术性和语义控制方面表现出色。
论文链接:https://arxiv.org/abs/2504.07963
整理:锦鲤
如需转载或投稿,请直接在公众号内留言